
Emergent Coordination through Game-Induced Nonlinear Opinion Dynamics

We explore the synergy between nonlinear opinion dynamics and trajectory games.
Key Research Contributions
We propose for the first time an automatic procedure for synthesizing nonlinear opinion dynamics (NOD) based on the value functions of a trajectory game. We show how the NOD effectively captures opinion evolution driven by the physical state of the system. For the two-player two-option case, we provide precise stability conditions for NOD equilibria based on the mismatch between opinions and game values, which depend on the physical states. Finally, we present a scalable, computationally efficient trajectory planning framework that computes agents’ policies guided by their evolving opinions such that coordination on tasks emerges.
Synthesizing Game-induced Nonlinear Opinion Dynamics (GiNOD)
Synthesizing a GiNOD model and using it for game-theoretic planning is efficient, scalable, and can be done online, which constitutes four steps:
Solve subgames with fixed options
Compute the gradient flow to obtain NOD parameters
Construct the GiNOD model
Solve the opinion-weighted QMDP for players’ control inputs
Theoretical Properties
We provide an in-depth analysis of GiNOD in the two-option, two-player setting. In particular, we show that GiNOD has the following properties:
Neutral opinions are unstable under high Price of Indecision
When agents have formed opinions that lead to better game values, those opinions are stable
If the game value is not influenced by opinions, the opinion dynamics are driven only by the damping term
Opinion-guided Game-theoretic Planning
Given a GiNOD model, we follow the QMDP principle and propose two game-theoretic planning methods:
Level-0 Opinion-guided QMDP: Follows the standard QMDP practice, optimistically assuming that the parameter uncertainties disappear in one step after the ego agent takes an action and that all opponents are clairvoyant playing their corresponding subgame policies
Level-1 Opinion-guided QMDP: Assumes other agents use the Level-0 policy and plans one more step to evolve opinion states, thus gaining an advantage in forming opinions and enabling active opinion manipulation
Results
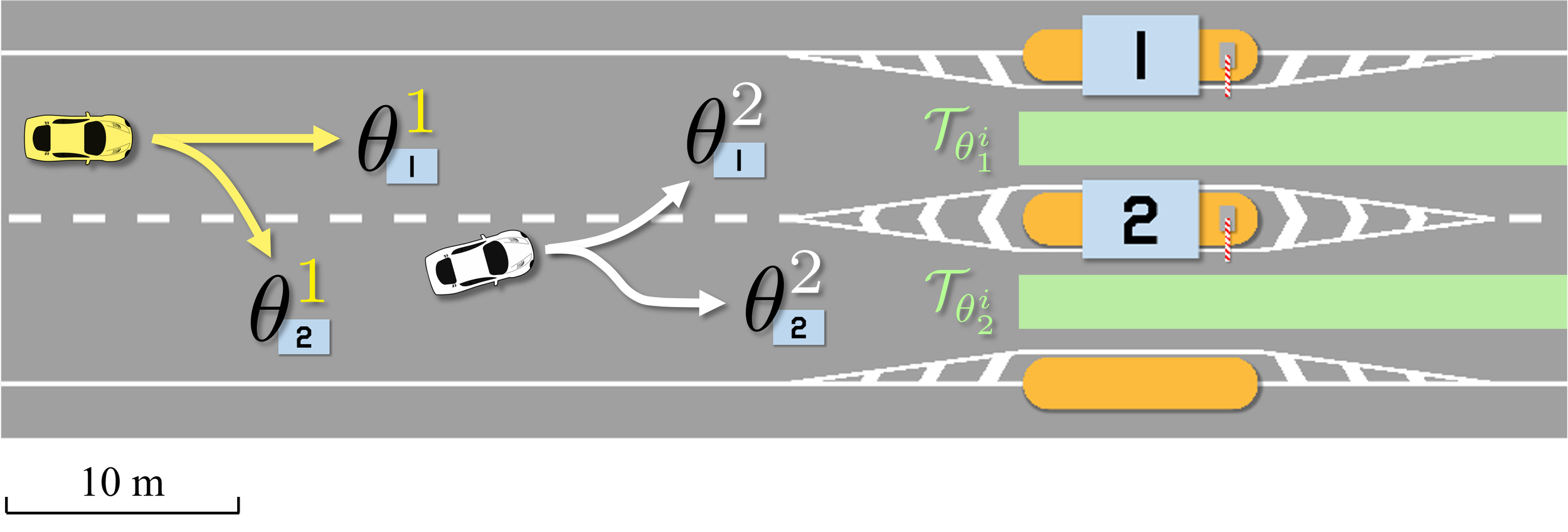


Running Example: Coordination at a Highway Toll Station
Consider two autonomous vehicles proceeding towards a toll station. The toll booths are modeled as static obstacles that the cars shall avoid. Additional safety-critical specifications include avoiding collisions with other vehicles and driving off the road. Agents’ opinions model their preference for either of the two toll booths.
We consider a set of heterogeneous cost weights, encoding that car 1 (yellow) prefers to go through toll booth 2, and car 2 (white) prefers to go through toll booth 1.
Level-0 QMDP
In the first trial, both cars use the Level-0 opinion-guided QMDP policy. Due to the interference from Car 2 (cutting in front of Car 1), Car 1 formed an opinion to stay in the left lane and went through the less preferred toll station. Nonetheless, both cars rapidly formed their opinions and completed the task safely without any collision.
Level-1 QMDP
In another trial under the same initial condition, we applied the Level-1 QMDP policy to Car 1 while keeping the Level-0 QMDP policy for Car 2. By leveraging the active opinion manipulation feature of the Level-1 policy, Car 1 was able to plan a more efficient trajectory toward its preferred toll booth.
@inproceedings{hu2023emergent,
title={Emergent Coordination through Game-Induced Nonlinear Opinion Dynamics},
author={Hu, Haimin and Nakamura, Kensuke and Hsu, Kai-Chieh and Leonard, Naomi Ehrich and Fisac, Jaime Fern\`andez},
booktitle={2023 62nd IEEE Conference on Decision and Control (CDC)},
year={2023},
}
Citation
Authors




